Sometimes when running a heavy query in Spark you can see that some stages are restarted multiple times and it may be difficult to understand information about stages in Spark UI.
Let’s consider a join of two large tables with the result written to Parquet files into some directory:
df = spark.sql("SELECT * FROM events e LEFT OUTER JOIN users u ON e.user_id = u.id")
df.write.parquet(location)
Before performing the join Spark launches two jobs to read data from the tables and then executes the join in a separate job with 3 stages:

For more details why this happens and how table read Stages 0 and 1 became Stages 2 and 3, see Spark AQE – Stage Numeration, Added Jobs at Runtime, Large Number of Tasks, Pending and Skipped Stages article.
In the driver log you can see that the join has started – Job 2, ResultStage 4:
23/10/01 12:28:59 INFO DAGScheduler: Got job 2 with 1000 output partitions 23/10/01 12:28:59 INFO DAGScheduler: Final stage: ResultStage 4 23/10/01 12:28:59 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 2, ShuffleMapStage 3) 23/10/01 12:28:59 INFO DAGScheduler: Submitting 1000 missing tasks from ResultStage 4 ... 23/10/01 12:28:59 INFO TaskSetManager: Starting task 0.0 in stage 4.0 ...
Stage Failure
Stage 4 has been starting its tasks and then a task failure happens:
23/10/01 12:28:59 INFO TaskSetManager: Starting task 0.0 in stage 4.0 ... 23/10/01 12:37:26 INFO TaskSetManager: Starting task 32.0 in stage 4.0 ... 23/10/01 12:37:26 WARN TaskSetManager: Lost task 14.0 in stage 4.0 message=org.apache.spark.shuffle.FetchFailedException 23/10/01 12:37:26 INFO TaskSetManager: task 14.0 in stage 4.0 failed, but the task will not be re-executed (either because the task failed with a shuffle data fetch failure, so the previous stage needs to be re-run, or because a different copy of the task has already succeeded).
Fetch Failure is one of error types when Spark aborts the execution of the current stage because it cannot get data from the previous stage that needs to be partially restarted to rebuild the missed data:
23/10/01 12:37:26 INFO DAGScheduler: Marking ResultStage 4 as failed due to a fetch failure from ShuffleMapStage 3 23/10/01 12:37:26 INFO DAGScheduler: ResultStage 4 failed due to org.apache.spark.shuffle.FetchFailedException
Restarting Parent Stages
As the shuffle files are lost, Spark has to restart the parent stages to read the missed data (RDD partitions) again:
23/10/01 12:37:26 INFO DAGScheduler: Resubmitting ShuffleMapStage 3 and ResultStage 4 due to fetch failure 23/10/01 12:37:26 INFO DAGScheduler: Submitting 285 missing tasks from ShuffleMapStage 3 23/10/01 12:37:26 INFO DAGScheduler: Submitting 23 missing tasks from ShuffleMapStage 2 ... 23/10/01 12:37:28 INFO TaskSetManager: Starting task 0.0 in stage 2.1 ... 23/10/01 12:39:03 INFO TaskSetManager: Starting task 0.0 in stage 3.1
Initially Stages 0 and 1 read the tables, but re-submit is performed for Stages 2 and 3 that have attempt 1 in Spark eventlog, and never have attempt 0.
Tasks of Failed Stage Continue to Run
Although Stage 4 (attempt 0) was stopped, it had started 32 tasks, 1 of them failed and caused the stage to stop, but other 31 tasks continue to run. New tasks are not launched but Spark does not terminate the running tasks, and moreover in case of successful completion it accepts their results.
Most remaining tasks of Stage 4.0 should most likely fail as any “reducer” needs data from all “mappers” unless they have been able to fetch the shuffle data before the node was lost.
In my case Stage 4.0 tasks continue to fail:
23/10/01 12:39:28 WARN TaskSetManager: Lost task 6.0 in stage 4.0 message=org.apache.spark.shuffle.FetchFailedException 23/10/01 12:39:28 INFO DAGScheduler: Resubmitting ShuffleMapStage 3 and ResultStage 4 due to fetch failure
You can see that Spark initiates one more resubmit, while Stage 3 has been already resubmitted and even running tasks.
Multiple Stage Resubmits
So if other nodes are lost or multiple executors were running on the lost node, you can observe that Stages 2 and 3 are resubmitted multiple times with different task sets before restarting Stage 4 (attempt 1):


Second Restart of Stage 4
Finally all Stage 2 and Stage 3 restarts are done and Stage 4 can be restarted:
23/10/01 13:11:37 INFO DAGScheduler: Submitting ResultStage 4, which has no missing parents 23/10/01 13:11:37 INFO DAGScheduler: Submitting 1000 missing tasks from ResultStage 4 ... 23/10/01 13:11:37 INFO TaskSetManager: Starting task 0.0 in stage 4.1 ... 23/10/01 13:13:24 INFO TaskSetManager: Starting task 911.0 in stage 4.1
It has managed to start 912 tasks when the successfully finished tasks started to appear:
23/10/01 13:13:13 INFO TaskSetManager: Finished task 16.0 in stage 4.1 (1/1000) 23/10/01 13:13:24 INFO TaskSetManager: Finished task 19.0 in stage 4.1 (2/1000) 23/10/01 13:13:26 INFO TaskSetManager: Finished task 17.0 in stage 4.1 (3/1000)
Stage Failure Again
Then suddenly a task fails again with FetchException:
23/10/01 13:20:07 WARN TaskSetManager: Lost task 7.0 in stage 4.1 message=org.apache.spark.shuffle.FetchFailedException 23/10/01 13:20:07 INFO DAGScheduler: ResultStage 4 failed due to org.apache.spark.shuffle.FetchFailedException
And again a resubmit is initiated:
23/10/01 13:20:07 INFO DAGScheduler: Resubmitting ShuffleMapStage 3 and ResultStage 4 due to fetch failure 23/10/01 13:20:07 INFO DAGScheduler: Submitting 472 missing tasks from ShuffleMapStage 3 23/10/01 13:20:07 INFO TaskSetManager: Starting task 0.0 in stage 3.3 ... 23/10/01 13:20:07 INFO TaskSetManager: Starting task 72.0 in stage 3.3 23/10/01 13:20:07 INFO DAGScheduler: Submitting 55 missing tasks from ShuffleMapStage 2 23/10/01 13:20:08 INFO TaskSetManager: Starting task 1.0 in stage 2.3 ... 23/10/01 13:20:08 INFO TaskSetManager: Starting task 54.0 in stage 2.3
At the same time the failed Stage 4 (Attempt 1) continues to run and can successfuly complete tasks what have been able to read the shuffle files before the node failure:
23/10/01 13:20:08 INFO TaskSetManager: Finished task 582.0 in stage 4.1 (751/1000) ... 23/10/01 13:20:27 INFO TaskSetManager: Finished task 650.0 in stage 4.1 (768/1000)
If you can check the target directory you can see that new files continue appearing from Stage 4 while restarts of Stage 2 and 3 are still running.
But some other tasks fail and cause more restarts:
23/10/01 13:20:37 WARN TaskSetManager: Lost task 22.0 in stage 4.1 message=org.apache.spark.shuffle.FetchFailedException
So because of these multiple restarts your Spark UI may look as follows:
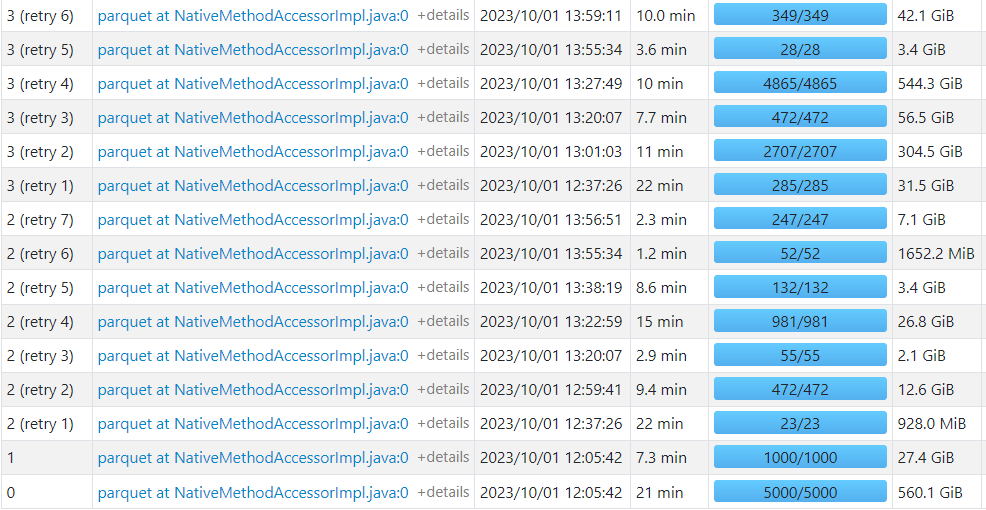
And for the join stage:

But thanks to partial retries the final attempt needed to run only 16 tasks:

Cost of Restarts
All these restarts are hidden from “the external world”, you can probably only notice some increase in query latencies i.e., but restarts are the wasted money.
While the number of restarted stages can look scary, you should actually check the total number of restarted tasks as stages are only partially restarted.
If ShuffleMapStages are restarted you should estimate the cost of 2nd, 3rd and subsequent attempts as they can read data from a cache i.e. while the intital successful attempt performs a real cold read, and ideally it should be the only one read.
ResultStage writes data to the final destination and the stage can be stopped when some tasks are already done (and they are not restarted) while other tasks has not been even started, so even if this stage is restarted most tasks are still executed once, and only failed tasks are restarted.
You can use SparkListenerTaskStart and SparkListenerTaskEnd events of Spark eventlog to get all necessary details:
Launch TimefromSparkListenerTaskStartandFinish TimefromSparkListenerTaskEndTask Type(ShuffleMapStageorResultStage) andStage Attempt IDfromSparkListenerTaskEnd
Then you can estimate the pure compute cost for restarted ShuffleMapStages stages (Stage Attempt ID > 0) as follows:
cost = sum(tasks_exec_seconds) * vcore_thread_cost_per_second
For example, if 10,000 tasks were restarted and ran for 300 seconds each (5 minutes) on EC2 EMR On-Demand r5d.2xlarge instances (8 vCores, $0.72 per hour):
cost = (10,000 tasks * 300 seconds) * ($0.72 hourly cost / 3,600 seconds / 8 vCores) = $75
For large environments running thousands of queries and millions tasks per day, even a small ratio of stage restarts can be expensive, so it should be monitored at scale.