Calculating the number of distinct values is one of the most popular operations in analytics and many queries even contain multiple COUNT DISTINCT expressions on different columns.
Most people realize that this should be a quite heavy calculation. But how is it really resource consuming and what operations are involved? Are there any bottlenecks? Can it be effectively distributed or just runs on a single node? What optimizations are applied?
Let’s see how this is implemented in Spark. We will focus on the exact COUNT DISTINCT calculations, so approximate calculations are out of scope in this article.
Consider the following typical SQL statement that contains multiple distinct and non-distinct aggregations:
SELECT COUNT(*), SUM(items), COUNT(DISTINCT product), COUNT(DISTINCT category) FROM orders;
For simplicity, we assume that the source data are read by two 1-core executors on two nodes and there are 8 rows:
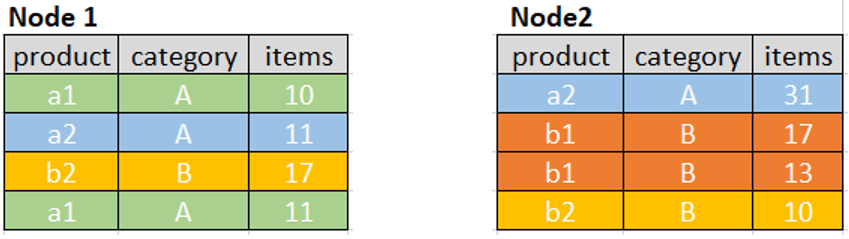
Expand
Spark transforms COUNT DISTINCT calculation into COUNT, and the first step is to expand the input rows by generating a new row for every distinct aggregation on different columns (product and category in our example) as well as 1 row for all non-distinct aggregations as follows:

Spark adds a group ID column gid with value of 0 that is used for all non-distinct aggregations (COUNT(*) and SUM(items) in our example), and separate group ID 1 and 2 for every distinct aggregation.
Note how NULL values are assigned: every row has only one non-NULL value for the input columns. In Spark physical plan you can see this operation as follows (simplified):
Expand
Input: [product, category, items]
Arguments: [
[null, null, 0, items],
[product, null, 1, null],
[null, category, 2, null]]
First HashAggregate
Then Spark locally hashes rows using all count distinct columns and group ID as the key (product, category and gid) and performs the partial local aggregation for non-distinct aggregations (COUNT(*) and SUM(items)):

This helps reduce the data volume after the expand operation. If the number of distinct values is low the reduction is very significant and the number of rows can be even lower than the number of the input rows.
You can see that intially there are 4 input rows per node, 12 rows after the expand, but then just 6 rows after the partial aggregation.
Shuffle and Second HashAggregate
Then these partially aggregated rows are shuffled between nodes, so all key values involved into aggregations become collocated, for example, it can be as follows:

And once again the second local hash aggregation is performed grouping by product, category and gid and calculating partial aggregations COUNT(*) and SUM(items) within each group:

This step allows to de-duplicate all keys involved into aggregations.
Final Result
Now the rows can be combined into a single partition (HashAggregation again but now without grouping by product, category and gid):

There are no duplicate values anymore, and a simple COUNT with gid filters can produce the desired COUNT DISTINCT result:
cnt FILTER (WHERE gid = 0), sum FILTER (WHERE gid = 0), COUNT(product) FILTER (WHERE gid = 1), COUNT(category) FILTER (WHERE gid = 2)
Result:
COUNT(*): 8 SUM(items): 120 COUNT(DISTINCT product): 4 COUNT(DISTINCT category): 2
Performance
- If the number of distinct values is low then the number of shuffled rows can be very low even after the expand operator, so COUNT DISTINCT can be relatively fast due to the local partial aggregations in Spark.
- If the number of distinct values is high and you use multiple COUNT DISTINCT for different columns or expressions in a single query then the number of shuffled rows can explode and become huge, partial aggregations cannot be effectively applied (few duplicate groups to reduce), so more executor memory can be required to complete the query successfully.
For more details about COUNT DISTINCT implementation in Spark, see the RewriteDistinctAggregates class of org.apache.spark.sql.catalyst.optimizer package.