Often incoming data contain timestamp values (date and time) in the string representation like
2023-07-28 12:50:22.087 i.e., and it is common to run queries with DATE filters as follows:
SELECT * FROM incoming_data WHERE SUBSTR(created_at, 1, 10) = '2023-10-09';
Let’s see what is wrong with such query filters if you read Parquet data in Spark.
No Pushed Filters
If you look at the physical plan of this query you can notice that Spark is unable to push the filter to Parquet:
+- Filter (isnotnull(created_at#132) AND (substr(created_at#132, 1, 10) = 2023-10-09))
+- ColumnarToRow
+- FileScan parquet
DataFilters: [isnotnull(created_at#132), (substr(created_at#132, 1, 10) = 2023-10-09)
PartitionFilters: [],
PushedFilters: [IsNotNull(created_at)]
The reason is that there is SUBSTR function that Parquet cannot evaluate when reading rows from data files and this needs to be done by Spark engine:

As you can see, in my case, the job read 3.7 billions rows from Parquet and after the filter is applied there are just about 1 million rows remain (about 0.03% of read data) meaning unnecessary read of 99.97% of rows.
Using LIKE Predicate
For this specific case when you know that the timestamp values are in the ISO format starting with YYYY-MM-DD you can replace SUBSTR(ts, 1, 10) with the LIKE predicate:
SELECT * FROM incoming_data WHERE created_at LIKE '2023-10-09 %';
Now the physical plan is as follows:
+- Filter (isnotnull(created_at#132) AND StartsWith(created_at#132, 2023-10-09))
+- ColumnarToRow
+- FileScan parquet
DataFilters: [isnotnull(created_at#132), (substr(created_at#132, 1, 10) = 2023-10-09)
PartitionFilters: [],
PushedFilters: [IsNotNull(created_at), StringStartsWith(created_at,2023-10-09)]
Fortunately ParquetFilters class (package org.apache.spark.sql.execution.datasources.parquet) responsible for the predicate push down supports pushDownStringStartWith expressions.
Now Parquet returns just 2.1 million rows before filtering out to the final 1 million rows by Spark. Here you can see that push down filtering is performed at row group level, not at row level by Parquet.
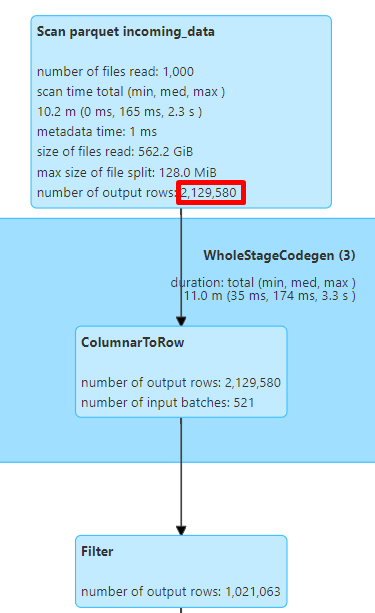
Note there is the spark.sql.parquet.filterPushdown.string.startsWith option in Spark (the default is true) to enable or disable the predicate pushdown for the leading substrings.
When It is Not Enough to Push Down Filters
In general, it is good when a filter can be pushed down to the Parquet engine, so data skipping can be applied. But the actual data organization is very important for such filtering to be effective.
Parquet uses MIN/MAX statistics for row groups and if data are not well sorted or ranged (every row group contains string values from ‘A’ to ‘z’ i.e.) then Parquet still needs to read all rows and pushed filters do not help improve the query performance.
If you see that push down filters are used but Spark continue reading a lot of rows before applying a filter, you can investigate your Parquet files metadata using parquet-tools:
hadoop jar parquet-tools-1.11.2.jar meta s3://cloudsqale/incoming_data/file_0500.parquet | grep created_at ... created_at: ... [min: 2020-03-14 00:17:44.33, max: 2020-03-14 19:23:31.967, num_nulls: 0] created_at: ... [min: 2021-10-29 01:33:53.985, max: 2021-10-29 10:50:33.829, num_nulls: 0] created_at: ... [min: 2023-04-08 06:23:31.959, max: 2023-04-08 07:44:53.385, num_nulls: 0]
For more details, see also Spark – Reading Parquet – Predicate Pushdown for LIKE Operator – EqualTo, StartsWith and Contains Pushed Filters article.