Global sorting is one the most important operations on data, and it is not only used to define how you can see the query result in UI but more importantly it is widely used to solve various performance issues in data pipelines i.e. to provide a better data compression, clustering, pruning and so on.
Let’s see how ORDER BY is implemented in Spark.
Distributed Sort
When you add an ORDER BY clause to your query Spark adds Sort and Exchange Range Partitioning nodes to the physical plan:
+- *(1) Sort [value#0 ASC NULLS FIRST]
+- Exchange rangepartitioning(value#0 ASC NULLS FIRST), ENSURE_REQUIREMENTS
This means that the sort is distributed and not running on a single node causing a significant performance impact.
The global sort in Spark internally uses range partitioning to assign sort keys to an ordered non-overlapping partition range. This involves collecting a sample from the input partitions, computing the range boundaries and then sending the output rows according to them.
Sampling
When there is ORDER BY in the query, Spark first runs a job (you can see it in the Spark UI) to sample input data.
The sample size per partition is controlled by spark.sql.execution.rangeExchange.sampleSizePerPartition option with the default value of 100 rows per shuffle (not input) partition:
sampleSize = spark.sql.execution.rangeExchange.sampleSizePerPartition * spark.sql.shuffle.partitions sampleSizePerInputPartition = 3 * sampleSize / number of input RDDs
Note that if Spark AQE is enabled the number of shuffle partitions is defined dynamically, not by the
spark.sql.shuffle.partitions option.
Reservoir Sampling Algorithm
You can expect that only 100 rows are read per partition for sampling, but this is not the case. Spark reads all rows and the sampling size just defines the size of array (reservoir) to hold sample rows.
Spark uses the Algorithm R for the reservoir sampling. Let’s assume there are 1,000 input rows and reservoir can just contain 10 rows:
1. Initially the reservoir is filled with the first 10 input rows.
2. All other input rows (11 to 1000) are scanned, and i-th row replaces an existing row in the reservoir with the decaying probability 10/i.
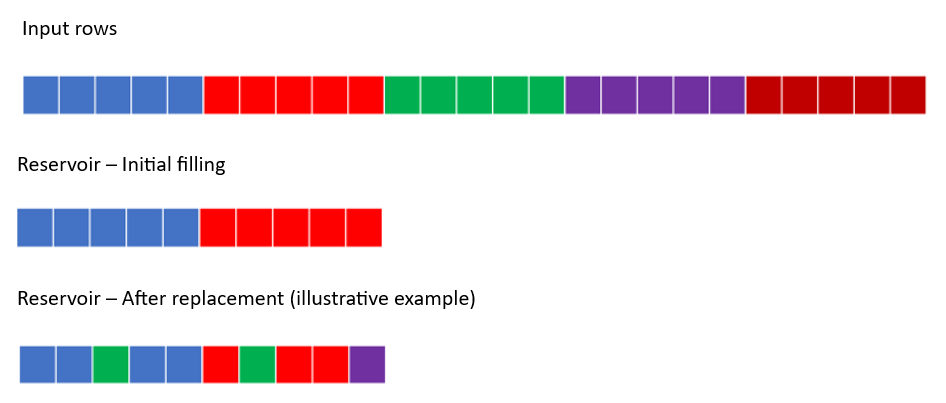
So although all rows are trialed, the reservoir is most likely filled with the initial rows.
Range Boundaries
After collecting sample rows, Spark sorts them by the sorting key (the columns specified in ORDER BY) and defines the upper boundary for each N-1 output shuffle partition.
Assume there are 6 input partitions and 3 rows are selected for samples:
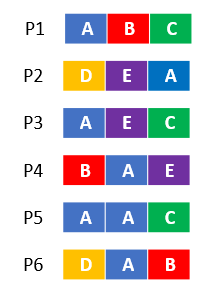
After the sorting, Spark takes into account the partition weights and duplicate keys to define the upper boundaries:

As the sample may not include all possible key values, lower and upper values will be assigned to the first and last output partitons, respectively.
Skew
As you can see although the global sort is distributed, range partitioning has a bottleneck if the sort keys are skewed i.e. few of them appear much more often in input than others.
It often happens, for example, when a company sells many products but the majority of orders come from a single product, or when devices send many events but one of them is very “noisy” and so on.
As the same key value must go to the same output shuffle partition (reducer), one shuffle partition has to process much more data that can cause increased latency for the entire stage.
If sort keys are skewed or you just have few distinct sort values (less than the desired number of output partitions or files), you can introduce a “salt” after the sort keys as follows:
ORDER BY col, CAST(RAND()*200 AS INT)
In the example above, every col value is now uniformly distributed as col, 0; col, 1; ... col, 199 values and can be handled in a distributed way still ensuring the global sorting.