With Spark Adaptive Query Execution (AQE) the application view becomes very dynamic in Spark UI and information about jobs and stages may look very confusing: new jobs appear from time to time, the estimated number of tasks is high, there are pending parent stages that suddenly become skipped and so on.
Let’s consider a simple query joining two tables and how its execution appears in Spark UI:
SELECT * FROM events JOIN users ON user_id = id
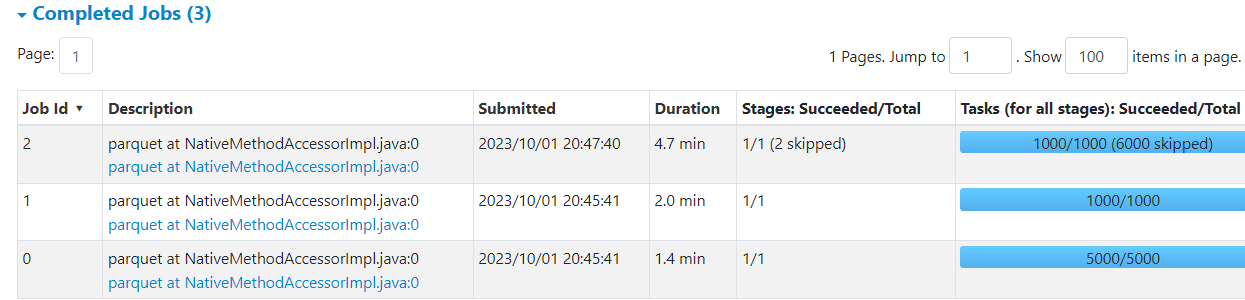
Two Jobs to Read Tables
Initially Spark starts two separate jobs to read data for each table used in the join:
This is required to collect statistics and to be able to modify the physical plan for the upcoming join stage.
Note that Spark UI still does show any job to perform the actual join.
Join
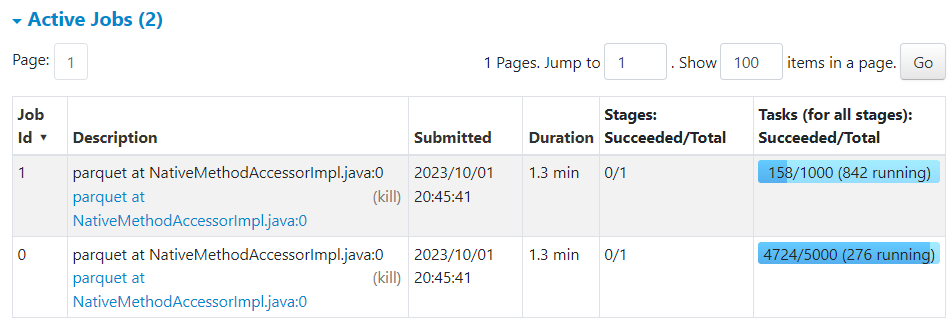
When the table reads complete, Spark launches a job to perform the join and now you can see it in Spark UI:
Spark UI shows that this join job consists of 7,000 tasks (!) in 3 stages:

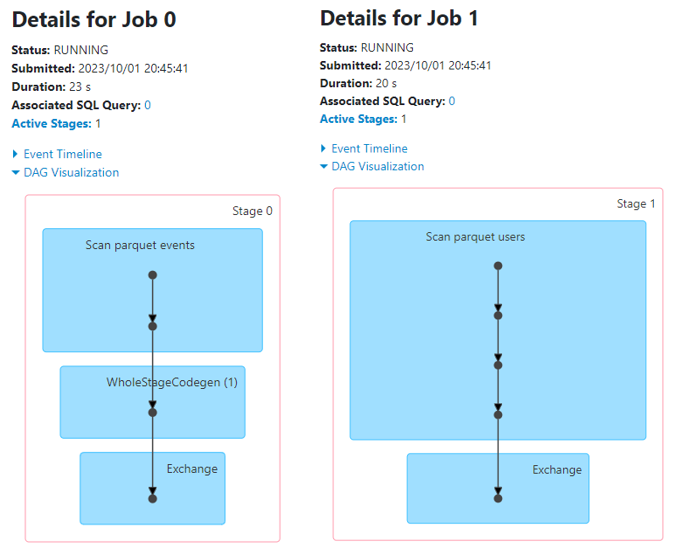
Below in Spark UI you can see that Stage 4 already started and its parent (!) Stages 2 and 3 are marked as pending:
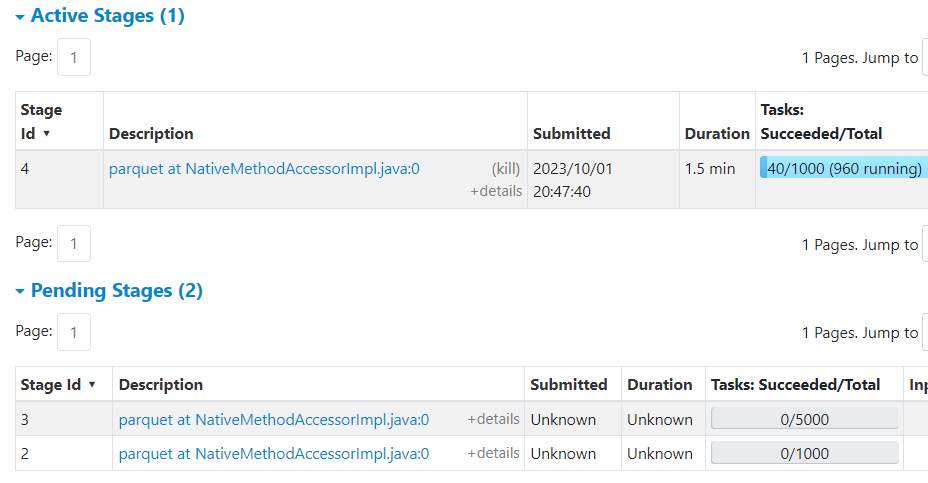
The reason is that Stages 2 and 3 actually correspond to Stages 0 and 1 that were already executed, but Spark UI (at least as of version Spark 3.3) cannot recognize this and as it has not received any events about their start, it marked them as pending.
This also lead to increased number of tasks 7,000 instead of 1,000 shown to be executed by Job 2. This is Spark UI “bug” as Spark AQE engine actually has no plans to execute them (unless a stage restart is required in case of a failure i.e. FetchFailedException).
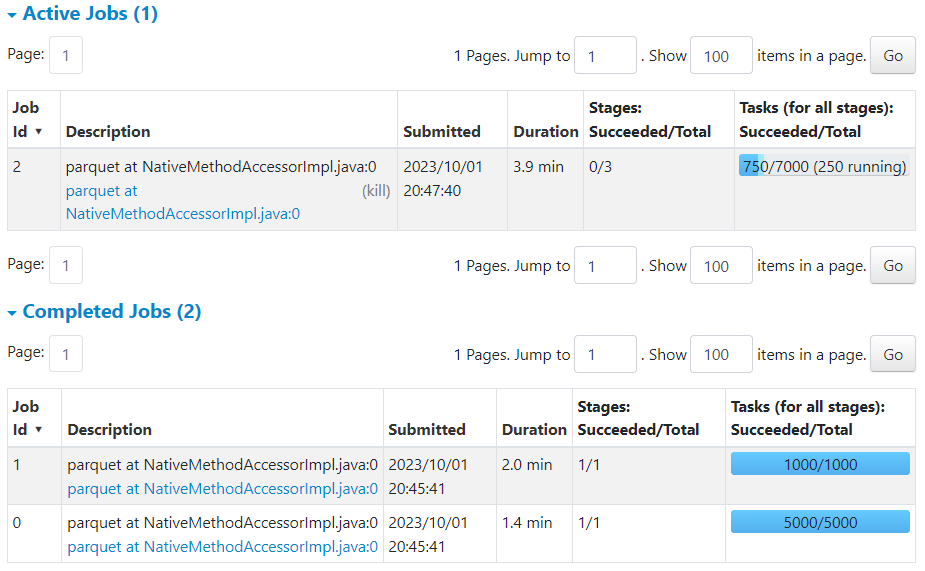
When the job finishes you can see that stages 2 and 3 are just marked as skipped. It is a feature of Spark UI to mark all pending stages from a completed job as skipped.
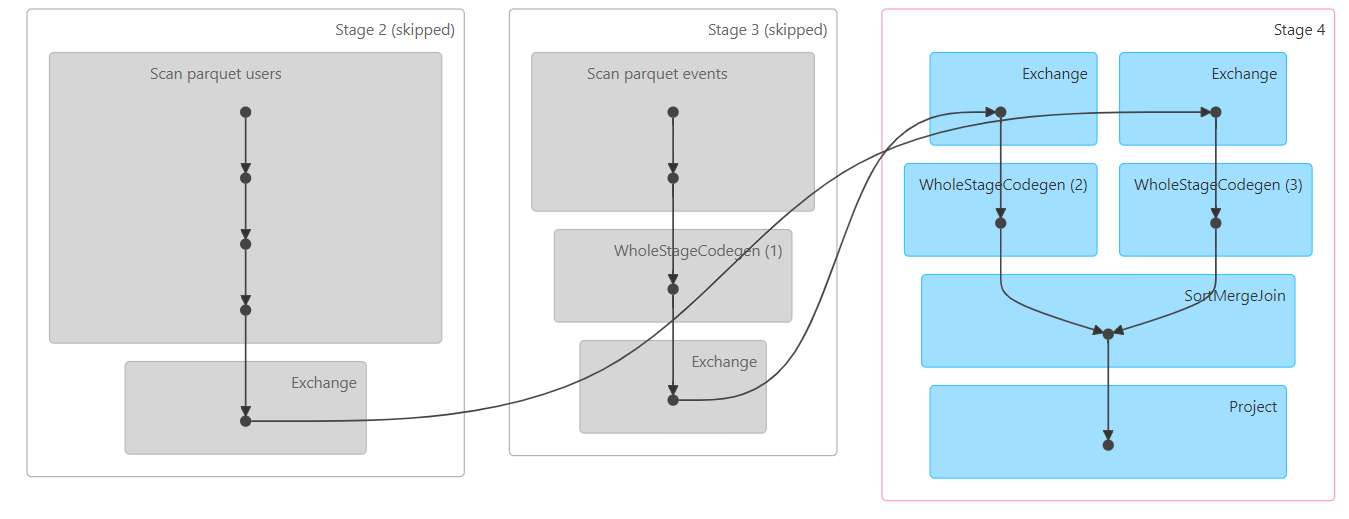
So for the join query Stages 0, 1, and 4 were only executed.
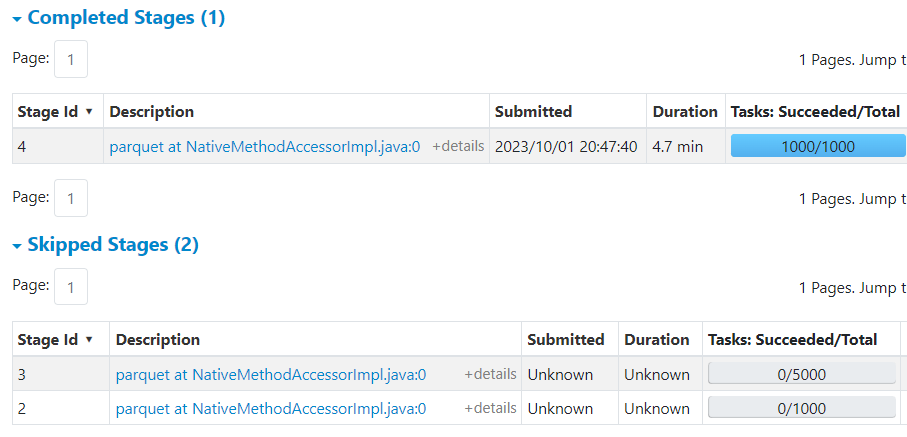
Finally when all jobs are completed Spark UI shows the correct number of executed tasks, although 6,000 skipped tasks may still be confusing: