One of the powerful features of Presto is auto scaling of compute resources for already running queries. When a cluster is idle you can reduce its size or even terminate the cluster, and then dynamically add nodes when necessary depending on the compute requirements of queries.
Unfortunately, there are some limitations since not all stages can scale on the fly, so you have to use some workarounds to have reasonable cold start performance.
Let’s consider the following typical query:
SELECT product, COUNT(DISTINCT user_id) FROM events GROUP BY product
A simplified EXPLAIN (TYPE DISTRIBUTED) plan for this query:
Fragment 1 [HASH]
Output layout: [product, count]
Output partitioning: SINGLE []
- Aggregate(FINAL)[product]
- LocalExchange[HASH]
- RemoteSource[2]
Fragment 2 [HASH]
Output partitioning: HASH [product]
- Aggregate(PARTIAL)[product]
- Aggregate(FINAL)[product, user_id]
- LocalExchange[HASH]
- RemoteSource[3]
Fragment 3 [SOURCE]
Output partitioning: HASH [product, user_id]
- Aggregate(PARTIAL)[product, user_id]
- ScanProject[table = events]
First, let’s review each stage (fragment) in detail.
Fragment 3 [SOURCE]
Fragment 3 [SOURCE] reads the data from the source table and performs a partial aggregation. In my example, every task removes duplicates (product, user_id) in its own data chunk (input split).
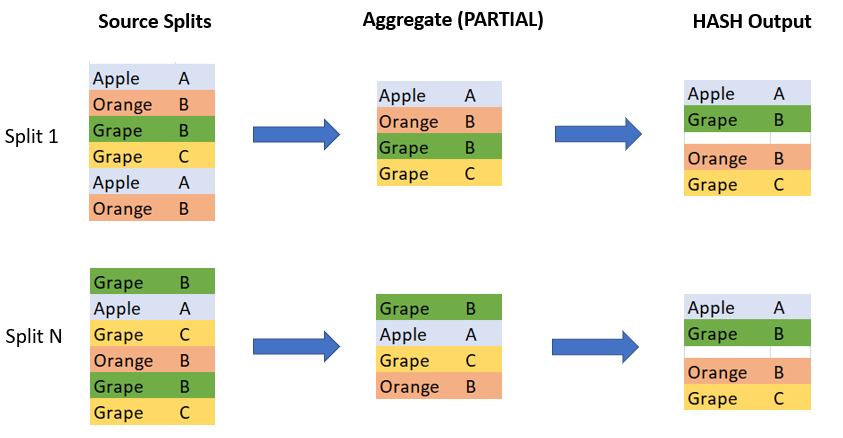
Note that at this stage the duplicates are removed locally within each task. In some cases it can significantly reduce the amount of data to be sent over network to Fragment 2.
Fragment 2 [HASH]
Fragment 2 gets hashed (product, user_id) pairs shuffled from the previous stage that means the tasks of this stage can now remove duplicate (product, user_id) for the entire input data set.
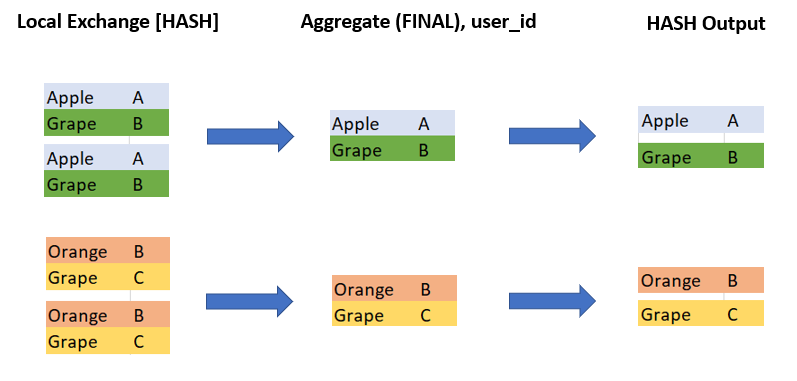
So as a result if we combine data on all workers we have unique pairs of (product, user_id) hashed by product.
Fragment 1 [HASH]
Fragment 1 gets unique (product, user_id) pairs but since they are also hashed by product, each task of this stage can simply count the number of user_id per product to get the required COUNT DISTINCT.

Query Execution
When the query started the cluster has 2 workers, so Presto created 2 tasks for each stage:

There are many input splits so the cluster auto scaled to 50 nodes in about 5-10 minutes, but new tasks were created for Stage 3 only:
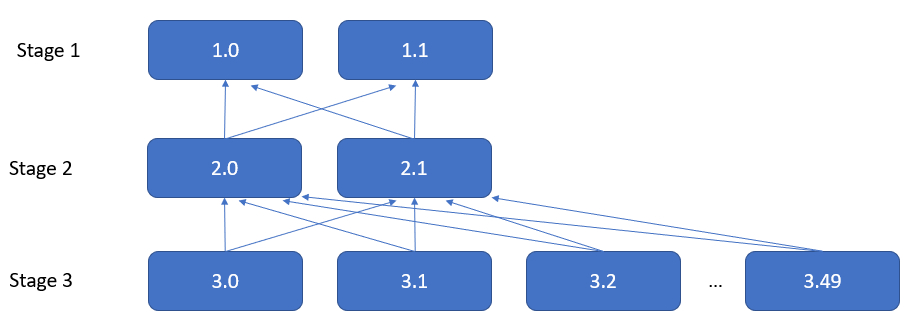
This can be also observed from the query stats:
Task ID State Splits Rows Bytes ------- ----- ------ ---- ----- 1.0 FINISHED 33 65.4K 4.25M 1.1 FINISHED 33 65.1K 4.23M 2.0 FINISHED 32 787M 62.2G 2.1 FINISHED 32 787M 62.2G 3.0 FINISHED 160 316M 5.60G 3.1 FINISHED 164 324M 5.74G 3.2 FINISHED 8 15.8M 287M 3.3 FINISHED 8 15.8M 287M 3.4 FINISHED 7 13.8M 251M 3.5 FINISHED 7 13.8M 251M ... 3.47 FINISHED 7 13.8M 251M 3.48 FINISHED 8 15.8M 287M 3.49 FINISHED 7 13.8M 251M
You can see that Stage 3 was auto scaled and new tasks were added – 3.2 to 3.49, while Stage 2 and Stage 1 continued running 2 tasks only, and became a bottleneck – Tasks 2.0 and 2.1 processed 1.5 billion rows (124.4 GB).
Currently Presto cannot upscale HASH stages.
Required Workers
Unfortunately, at the time of writing, the only solution for this problem is to specify the required number of workers before you run large queries.
There is the query-manager.required-workers option at the cluster level or session option required_workers (as of Presto 326 the session option is available in Qubole Presto only):
SET SESSION required_workers = 30; SELECT product, COUNT(DISTINCT user_id) FROM events GROUP BY product;
Now Presto first will auto scale the cluster to 30 nodes and then start the query. In this case Stage 2 and Stage 3 will run 30 tasks, not 2 tasks.
Conclusion
When a cluster is downscaled to the minimum number of nodes, and early bird users start running their queries they still may not benefit from the cluster upscale. Their queries can fail due to memory or disks errors, or even worse, they can progress very slowly which can negatively impact the user experience.
To mitigate such issues consider setting the minimal number of workers before running heavy queries on downscaled Presto clusters.