I was asked to tune a Hive query that ran more than 10 hours. It was running on a 100 node cluster with 16 GB available for YARN containers on each node.
Although the query processed about 2 TB of input data, it did a fairly simple aggregation on user_id column and did not look too complex. It had 1 Map stage with 1,500 tasks and 1 Reduce stage with 7,000 tasks.
All map tasks completed within 30 minutes, and the query stuck on the Reduce phase. So what was wrong?
YARN Memory
First I noticed that the job used only 100 containers i.e. just one container per cluster node. This was very suspicious as Hive uses the Apache Tez execution engine that can run concurrently only one task in a container.
Looking at the Hive script I found:
set hive.tez.container.size = 10240; -- 10 GB
Looks like someone had a memory problem with this query before and wanted to solve it once and forever!
Although the query probably will not fail with the “out of memory” error anymore, this setting allows allocating only one container per node since the cluster nodes have only 16 GB of memory and cannot allocate two 10 GB containers:

There were many pending containers but they could not run since 6 GB of free memory available on every node was not enough to allocate one more 10 GB container. So the cluster could allocate more memory but at the same time it was still highly underutilized as it had 6 * 100 = 600 GB of free memory across the cluster.
Since the Reduce stage had 7,000 tasks and only 100 could run concurrently it required 70 iterations or about 10 hours to run all reducers.
Adjusting Container Memory Size
After reduce tasks completed you can collect their COMMITTED_HEAP_BYTES counters to see how much memory was really needed. In my case this was less than 2 GB per task.
So I tried to reduce the container size as follows:
set hive.tez.container.size = 2048; -- 2 GB
Now each node can run 8 containers concurrently:
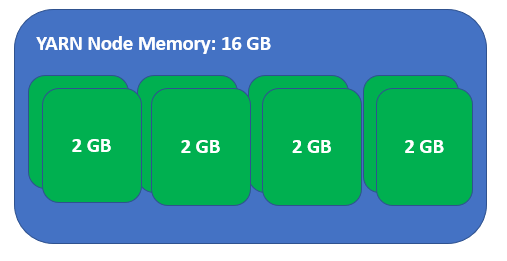
So smaller containers helped increase the task concurrency, overall utilization of the cluster and the query now completes in less than 2 hours.
Conclusion
Although use of large containers help get rid of memory problems for specific queries it can easily incur huge performance penalties for the entire cluster.
Not only a query with large containers books (and often does not use) the memory preventing other users to run their queries, but it also significantly decreases the concurrency of its own execution and increases the total execution time.
Since YARN does not directly support resource overcommit (but see some hacks in Boosting Memory Settings to Increase Cluster Capacity and Utilization) you have to track the actual memory requirements for your Hive queries and set the container size accordingly for optimal concurrency and utilization of your cluster.