Snowflake provides various options to monitor data ingestion from external storage such as Amazon S3. In this article I am going to review QUERY_HISTORY and COPY_HISTORY table functions.
The COPY commands are widely used to move data into Snowflake on a time-interval basis, and we can monitor their execution accessing the query history with query_type = 'COPY' filter.
Daily Summary
Let’s start reviewing the daily statistics for data ingestion. For example, you can use the following query:
SELECT SUBSTR(start_time, 1, 10) dt, COUNT(DISTINCT SPLIT(query_text, ' ')[2]) tbl_cnt, COUNT(*) copy_cnt, SUM(bytes_scanned)/(1024*1024*1024) scanned_gb, SUM(rows_produced)/1000000 rows_mln, (SUM(bytes_scanned)/(1024*1024))/(SUM(execution_time)/1000) rate_mbs, SUM(rows_produced)/(SUM(execution_time)/1000) rows_sec FROM TABLE(information_schema.query_history_by_warehouse(WAREHOUSE_NAME => 'ETL_LOAD_WH', RESULT_LIMIT => 10000)) WHERE query_type = 'COPY' GROUP BY SUBSTR(start_time, 1, 10)
It shows the number of tables transferred, COPY commands executed as well as various performance statistics. For example:
| dt | tbl_cnt | copy_cnt | scanned_gb | rows_mln | rate_mbs | rows_sec |
|---|---|---|---|---|---|---|
| 2019-05-08 | 22 | 224 | 1186 | 6361.3 | 18.8 | 98722.6 |
| 2019-05-09 | 24 | 247 | 1211 | 6718.6 | 23.5 | 127549.1 |
| 2019-05-10 | 24 | 240 | 1064 | 6122.3 | 19.6 | 110410.8 |
Daily statistics helps you get a general impression about the data ingestion. In my case, you can see that data were loaded into 22-24 tables, the total size is 1.0-1.2 TB, and the total number of rows is 6.1-6.7 billion per day.
While the daily summary can show unexpected data growth, critical performance issues, it does not point to any transfer problems that can exist for some tables only.
Table Level Summary
Let’s continue investigating data ingestion at the table level. For example, you can use the following query to get a summary for tables larger than 1 GB for the specified date:
SELECT split(query_text, ' ')[2] tbl, COUNT(*) copy_cnt, SUM(execution_time)/(1000*60*60) exec_hours, SUM(bytes_scanned)/(1024*1024*1024) scanned_gb, SUM(rows_produced)/1000000 rows_mln, (SUM(bytes_scanned)/(1024*1024))/(SUM(execution_time)/1000) rate_mbs, SUM(rows_produced)/(SUM(execution_time)/1000) rows_sec FROM TABLE(information_schema.query_history_by_warehouse(WAREHOUSE_NAME => 'ETL_LOAD_WH', RESULT_LIMIT => 10000)) WHERE query_type = 'COPY' and SUBSTR(start_time, 1, 10) = '2019-05-09' and BYTES_SCANNED > 1024*1024*1024 GROUP BY SUBSTR(start_time, 1, 10), split(query_text, ' ')[2]
You can see how may COPY commands were executed for each table, the total data transfer time, the table size, the number of rows and some performance metrics:
| tbl | copy_cnt | exec_hours | scanned_gb | rows_mln | rate_mbs | rows_sec |
|---|---|---|---|---|---|---|
| logs | 124 | 2.9 | 273.6 | 396.1 | 26.2 | 37100.6 |
| sites | 22 | 4.0 | 38.8 | 519.0 | 2.7 | 35827.7 |
| events | 1 | 0.05 | 28.4 | 209.1 | 155.2 | 1113648.3 |
| clicks | 30 | 0.57 | 391.2 | 1030.1 | 192.0 | 493857.0 |
Here you can notice that it took 4 hours to load 38.8 GB to sites table and that was very slow compared with other tables.
One of the typical reasons of slow COPY performance is the lack of parallelism in Snowflake. Currently Snowflake is only able to automatically parallel copy operation if you load multiple files.
If all your data are in a single large file then Snowflake will run only one copy operation for the entire file, so the load can be very slow and you can heavily under-utilize the cluster resources.
You can use the COPY_HISTORY table function to investigate how many files were loaded for the specified table.
For example, for sites table:
SELECT
FILE_NAME,
LAST_LOAD_TIME,
ROW_COUNT,
FILE_SIZE
FROM TABLE(information_schema.copy_history('SITES', '2019-05-09 00:00:00'::TIMESTAMP_LTZ,
'2019-05-09 23:59:59'::TIMESTAMP_LTZ))
I can see that hourly load includes single file data.gz only:

At the same time if I execute the same query for clicks table, I see that its load includes 92 files and this explains why it has much higher performance:
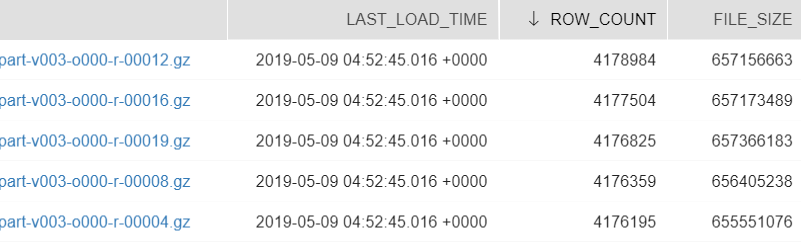
In the first case it was an export file from a PostgreSQL database while in the second case it was the result of a Map Reduce job that naturally produces multiple files.
When I changed my PostgreSQL export script to generate multiple files (one file per 1M rows) I get 30 files instead of 1:
psql -h $PG_HOST -U $PG_USER -d $PG_DB -c "copy (SELECT * FROM sites) to stdout" | split -l 1000000 --filter='gzip > $FILE.gz' - "$TMP_PATH/sites_"
After that change the export time into Snowflake reduced from 12 minutes to less than 1 minute:
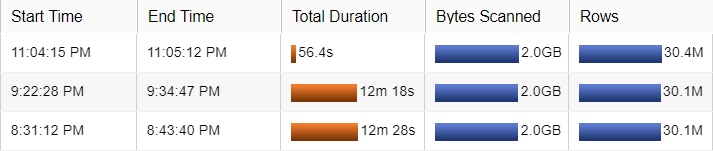
The transfer of sites table took 4 hours per day, now it is just 24 minutes. This helps save 3.5 credits per day, it is more than 1,250 per year (~$2,500).
Side Note: If you dedicated a Medium or X-Large cluster to COPY workloads, and they all run at the different time frames, then this single file copy job prevents the entire 4-16 node cluster from suspension during 4 hours per day. All the remaining nodes are idle but you still have to pay for them. So by running parallel copy and reducing the elapsed time you can probably save even more.
I suggest that you monitor your daily ingestion, find out jobs copying single large files and try to split them before loading into Snowflake. This can help significantly reduce the time and the compute cost.