Snowflake separates compute and storage, so it is typical to have a dedicated compute cluster (virtual warehouse) to handle data ingestion into Snowflake (if you do not use Snowpipe).
Like reporting and Ad-hoc SQL, data ingestion has some specifics. Usually there are many tables (data sources) that have own schedule (daily, hourly, every 5, 10, 15 minutes etc.) for periodic data transfer. ETL processes can be overlapped, and can have spikes followed by idle time and so on.
At the same time you still can see the flat usage of cluster resources from your billing report:

But does this reflect the actual utilization for ETL processes? Can we be sure that the cluster is fully busy?
Using the Snowflake query history and some SQL tricks with a time dimension table (hour_minute_dimension contains 1 row for every minute of day – from 00:00 to 23:59), you can get minute-by-minute picture of commands executed in Snowflake:
SELECT
ARRAY_AGG(query_type) query_type,
hour_minute
FROM (
SELECT
query_type,
start_time,
end_time
FROM TABLE(information_schema.query_history_by_warehouse(WAREHOUSE_NAME => 'ETL_WH',
RESULT_LIMIT => 10000))
WHERE SUBSTR(start_time, 1, 10) = '2019-05-11'
) t
INNER JOIN hour_minute_dimension d
ON d.hour_minute BETWEEN SUBSTR(start_time, 12, 5) AND SUBSTR(end_time, 12, 5)
GROUP BY hour_minute
ORDER BY hour_minute;
In my tests you can see that many short-lived COPY commands (micro-batch ingestion) are executed concurrently, but there are many 2-4 minute gaps when nothing is executed on the cluster:
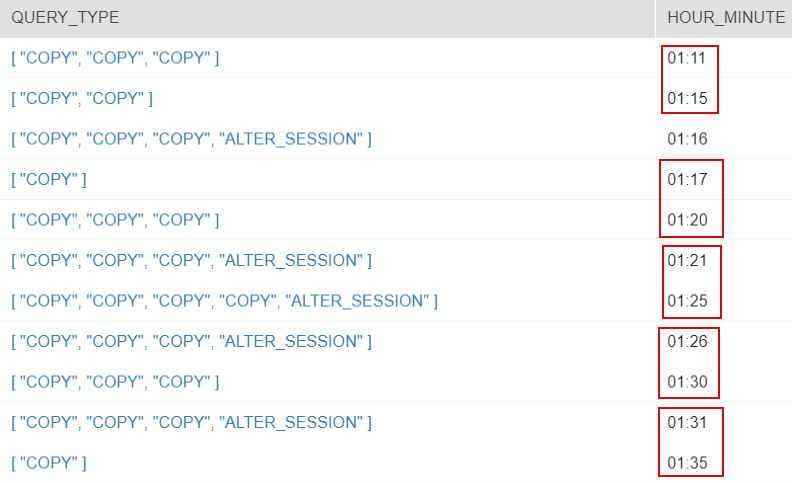
When I calculate count(distinct hour_minute) for the above query, I get only 931 minutes in that day when Snowflake was running a command. This means that actual cluster utilization was only 65% (931 of 1440 minutes in 24 hours).
I have the auto-suspend after 15 minutes of inactivity for my cluster that explains why I have full utilization for every hour.
For a X-Large warehouse that consumes 384 credits per day, I can potentially save up to 135 credits daily. It is about 50,000 credits per year ($100,000) for the cluster that is never suspended.
How to Optimize Data Ingestion Utilization
-
Check the auto-suspension time specified for the cluster (the default is 10 minutes). If your cluster does not execute commands continuously, but has 20-60 minutes suspension time it may actually never suspend.
Since dedicated data ingestion clusters are not used to execute user queries, they do not need to keep the data cache and you can reduce the auto-suspension time to very low values. Snowflake resumes clusters quickly (usually within 1-2 minutes) but you still have to monitor QUEUED_PROVISIONING_TIME metric for your commands.
Side Note: The time spent by Snowflake to resume the cluster can additionally buffer incoming COPY requests, and then run them concurrently even more utilizing the cluster to the full extent. This can increase the latency of individual commands, but can reduce the total compute cost.
- Combine short-lived COPY commands into larger data transfer operations. Reorganize the scheduling to avoid “fragmentation” of compute resource usage so you do need to run the data ingestion clusters continuously.