Apache Tez is the main distributed execution engine for Apache Hive and Apache Pig jobs.
Tez represents a data flow as DAGs (Directed acyclic graph) that consists of a set of vertices connected by edges. Vertices represent data transformations while edges represent movement of data between vertices.
For example, the following Hive SQL query:
SELECT u.name, sum_items FROM ( SELECT user_id, SUM(items) sum_items FROM sales GROUP BY user_id ) s JOIN users u ON s.user_id = u.id
and its corresponding Apache Pig script:
sales = LOAD 'sales' USING org.apache.hive.hcatalog.pig.HCatLoader();
users = LOAD 'users' USING org.apache.hive.hcatalog.pig.HCatLoader();
sales_agg = FOREACH (GROUP sales BY user_id)
GENERATE
group.user_id as user_id,
SUM(sales.items) as sum_items;
data = JOIN sales_agg BY user_id, users BY id;
Can be represented as the following DAG in Tez:

In my case the job ran almost 5 hours:
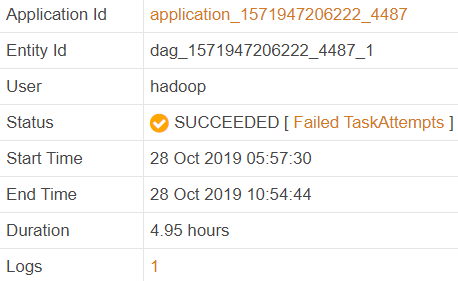
Why did it take so long to run the job? Is there any way to improve its performance?