Let’s see how Apache Tez defines the number of map tasks when you execute a SQL query in Hive running on the Tez engine.
Consider the following sample SQL query on a partitioned table:
select count(*) from events where event_dt = '2018-10-20' and event_name = 'Started';
The events table is partitioned by event_dt and event_name columns, and it is quite big – it has 209,146 partitions, while the query requests data from a single partition only:
$ hive -e "show partitions events" event_dt=2017-09-22/event_name=ClientMetrics event_dt=2017-09-23/event_name=ClientMetrics ... event_dt=2018-10-20/event_name=Location ... event_dt=2018-10-20/event_name=Started Time taken: 26.457 seconds, Fetched: 209146 row(s)
Partition Pruning and Input Paths
Before executing a query Hive tries to avoid reading unnecessary data. This process is called the partition pruning, it is performed in the Hive driver before launching any jobs in YARN, and you can see the following message in hive.log:
2018-10-20T08:53:28,178 DEBUG PartitionPruner.java:prune Filter w/ compacting: ((event_dt = '2018-10-20') and (event_name = 'Started')) 2018-10-20T08:53:30,523 DEBUG GenMapRedUtils.java:setMapWork Adding s3://cloudsqale/hive/events.db/events/event_dt=2018-10-20/event_name=Started of table events
So you can see that only one directory was added as Input Path for the Tez job.
Input Splits
After input paths (list of directories containing input data files) for the job are defined, Tez defines input splits – the minimal fraction of data that must be processed by a single Map task (i.e. it cannot be further divided to be processed by multiple Map tasks).
Note that some data formats (for example, compressed .gz files) are not splittable, and no matter what is the size of the file (1 KB or 1 GB) it will always comprise only one split.
In my case, events table contains data for raw events exported from an external data source, so each partition has a quite large number of relatively small .gz files:
$ aws s3 ls s3://cloudsqale/hive/events.db/event_dt=2018-10-20/event_name=Started/ --summarize 2018-10-20 04:41:01 51912591 00000.gz 2018-10-20 04:45:21 51896115 00001.gz 2018-10-20 04:42:35 52141658 00002.gz ... 2018-10-20 04:27:40 1115071 08644.gz 2018-10-20 04:27:26 2042 08645.gz Total Objects: 8646 Total Size: 180038369205
Tez engine performs input splits computation in the Application Master container.
By default Tez uses HiveInputFormat (this is defined by hive.tez.input.format option with the default value org.apache.hadoop.hive.ql.io.HiveInputFormat) to generate input splits:
From the Application Master log:
[INFO] [InputInitializer|io.HiveInputFormat|: Generating splits for dirs: s3://cloudsqale/hive/events.db/event_dt=2018-10-20/event_name=Started [INFO] [InputInitializer]|mapred.FileInputFormat|: Total input paths to process : 8646 [INFO] [InputInitializer]|io.HiveInputFormat|: number of splits 8646 [INFO] [InputInitializer]|tez.HiveSplitGenerator|: Number of input splits: 8646. 479 available slots, 1.7 waves. Input format is: org.apache.hadoop.hive.ql.io.HiveInputFormat
As expected the number of splits is equal to the number of .gz files in the partition directory.
Grouping Input Splits
Tez does not create a Map task for every input split as it may lead to a very large number of Map tasks processing small volumes of data with significant overhead required to allocate and run YARN containers.
Instead Tez tries to group the input splits to process them with a smaller number of Map tasks.
In the log above, you can see 479 available slots. Before running a job, Tez requests the available memory from YARN (headroom):
[INFO] rm.YarnTaskSchedulerService|: App total resource memory: 690176 cpu: 1 taskAllocations: 0
Tez AM also knows how much memory will be requested by every Tez container:
[INFO] impl.VertexImpl|:[Map 1], Default Resources=<memory:1440, vCores:1>
And 690176/1440 gives us 479 slots i.e. the estimated number of YARN containers that are available right now and can be executed in parallel.
Split Waves
After defining the number of available slots, Tez uses the split-waves multiplier (defined by the option tez.grouping.split-waves with the default value 1.7) to define the estimated number of Map Tasks: 479*1.7 gives us 814 tasks:
[INFO] [InputInitializer] |tez.SplitGrouper|: Estimated number of tasks: 814 for bucket 1 [INFO] [InputInitializer] |grouper.TezSplitGrouper|: Desired numSplits: 814 lengthPerGroup: 221177357 totalLength: 180038369205 numOriginalSplits: 8646 . Grouping by length: true count: false
Actual Number of Tasks
So far we got the estimated number of tasks 814 based on the resource availability and the wave multiplier.
Tez uses this value to define lengthPerGroup, the number of input bytes per task: totalLength/814 = 180038369205/814 = 221177357
Then Tez checks that lengthPerGroup is within the range defined by tez.grouping.min-size and tez.grouping.max-size options (50 MB and 1 GB by default).
If lengthPerGroup is less than tez.grouping.min-size it is set to tez.grouping.min-size. And if lengthPerGroup is greater than tez.grouping.max-size it is set to tez.grouping.max-size.
As the next step Tez iterates input splits and combines them making sure the group size does not exceed lengthPerGroup.
Since it is unlikely that groups will have exactly lengthPerGroup (in our case 221177357 bytes), actual number of tasks can differ from the estimated number 814:
[INFO] [InputInitializer] |grouper.TezSplitGrouper|: Number of splits desired: 814 created: 890 [INFO] [InputInitializer] |tez.SplitGrouper|: Original split count is 8646 grouped split count is 890 [INFO] [InputInitializer] |tez.HiveSplitGenerator|: Number of split groups: 890 ... [INFO] [App Shared Pool] |impl.VertexImpl|: Vertex [Map 1] parallelism set to 890
From Tez UI view:
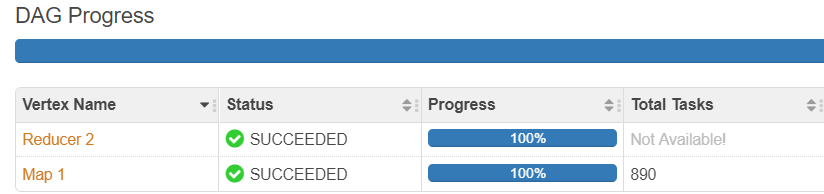
So in our case 890 Map tasks instead of 814 was created to process 8646 input files.
More About Split Waves – Key to Dynamic Allocation and Better Parallelism
You may wonder why to create more tasks than available YARN resources (free right now, not total resources in the cluster)? In our sample there are 479 available slots while Tez created 890 tasks.
It gives more freedom to allocate resources dynamically: some other jobs may terminate and free resources (although the opposite is also true), or the cluster can auto scale. So even if not all Map tasks start immediately they can catch up soon.
Another reason is that some Map Tasks can run much slower (because of the container performance or due to specifics of processing logic in Map Task that can depend on processed data i.e.), and in this case it is better to have a larger number of Map tasks processing smaller volumes of data each.
This helps avoid situations when most Map tasks already ended while few others still running, and the total execution time for the SQL query is high.
Why good values for tez.grouping.split-waves are 1.7, 2.7, 3.7 i.e. not the whole numbers? The reason is that we want the final wave to be smaller and cover only slow tasks.