Spark offers a very convenient way to read JSON data. But let’s see some performance implications for reading very large JSON files.
Let’s assume we have a JSON file with records like:
{"a":1, "b":3, "c":7}
{"a":11, "b":13, "c":17}
{"a":31, "b":33, "c":37, "d":71}
Schema Inference
When you use spark.read.json to read a JSON file, Spark is able to automatically infer the schema:
df = spark.read.json("sample.json")
df.show()
Result:
a b c d
---- ---- ---- ----
1 3 7 NULL
11 13 17 NULL
31 33 37 71
Spark discovers that a new d column is added in the 3rd row, and sets its value to NULL in all other rows where it is not defined. Unlike JSON you cannot have a variable list of columns in a dataframe or table.
Note that the inferrence job is immediately started when you define a data frame, before you run any Spark actions like show(), collect() etc.
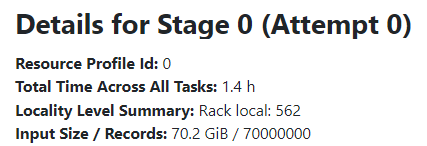
For example, for one of my large JSON files:
df = spark.read.json("s3://cloudsqale/items.json")
[Stage 0:==================================> (369 + 165) / 562]

Sampling
By default, when the JSON schema is not provided explicitly, Spark runs a job to read the entire JSON file (or directory) as a text file source, parses every row as JSON, performs the schema inference and merge. That is why Spark is able to discover new columns.
Of course this can be quite expensive if you have a very large JSON data set.
SamplingRatio Option
Spark provides the samplingRatio option to define the fraction of data set to read to infer the schema. By default samplingRatio option is 1.0 that is why the full file is read.
You may expect that if you specify samplingRatio 0.01 Spark will just read first 1% of rows, infer the schema and the problem is gone?
This is not how it works. Spark adds a Sample node to the Logical Plan that is translated to SampleExec node in the Physical Plan. During the execution Spark still has to read all rows, but then it performs a Bernoulli trial for every row i.e. applying samplingRatio probability that a row passes the filter.
But anyway there is some performance improvement of using the samplingRatio option: although Spark has to read all text rows, it needs to apply a JSON parser only for the selected rows.
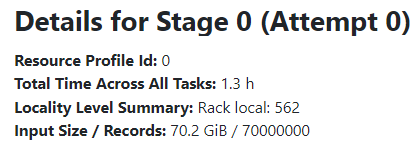
For example, for the same JSON file:
df = spark.read.option("samplingRatio", 0.01).json("s3://cloudsqale/items.json")
[Stage 0:=================> (184 + 100) / 562]

Issues
Another problem with the samplingRatio option is that if the JSON schema evolves, for example, new columns are added, they may be missed from the output if they are not included to the sample.
Consider the following example:
df = spark.read.option("samplingRatio", 0.1).json("sample.json")
df.show()
Result:
a b c
---- ---- ----
1 3 7
11 13 17
31 33 37
You can see that the d column is completely missed even when it has data in the 3rd row.
Spark UI and Eventlog
In Spark UI the JSON sampling job has a name like json at someClass.java. But unfortunately in Spark UI you cannot see whether the samplingRatio option is applied or not, it always shows all rows (see Records in the two screenshots above).
Spark Eventlog file allows you to see some sampling metrics in events SparkListenerTaskEnd or SparkListenerStageCompleted:
internal.metrics.input.recordsReadcontains all records- Job with
samplingRatio = 1hasnumber of output rowsmetric that contains all records - Job with
samplingRatio < 1has twonumber of output rowsmetrics, one of them contains all records and another selected records
For example, for my large JSON file:
"Accumulables": [{
"ID": 1,
"Name": "number of output rows",
"Value": "699835", ...
}, ...
{
"ID": 3,
"Name": "number of output rows",
"Value": "70000000", ...
}, ... ]
Unfortunately, the sampling job does not use SQLExecution so there is no Physical Plan in the eventlog file to match the accumulator IDs with the corresponding plan nodes.
Explicit Schema
So it is better to provide the schema explicitly, for example:
df = spark.read.schema("a string, c string, d string").json("sample.json")
df.show()
Result:
a c d
---- ---- ----
1 7 NULL
11 17 NULL
31 37 71
In this case Spark does not need to launch a job to infer the schema. Additionally you can include only columns that you need to process (b column is excluded in my example above), no need to include all columns from JSON.
For more information about JSON sampling and schema inference, see
- Method
inferSchemaofJsonFileFormatclass - Method
inferFromDatasetofJsonDataSourceclass - Method
sampleofJsonUtilclass - Method
sampleofDatasetclass - Class
SampleinbasicLogicalOperators.scala - Class
SampleExecinbasicPhysicalOperators.scala - Method
randomSampleWithRangeinRDD.scala - Classes
RandomSamplerandBernoulliCellSamplerinRandomSampler.scala