It is quite typical to write the resulting data into a partitioned table, but performance can be very slow compared with writing the same data volume into a non-partitioned table.
Let’s investigate why it is slow, and why the sorting operation happens.
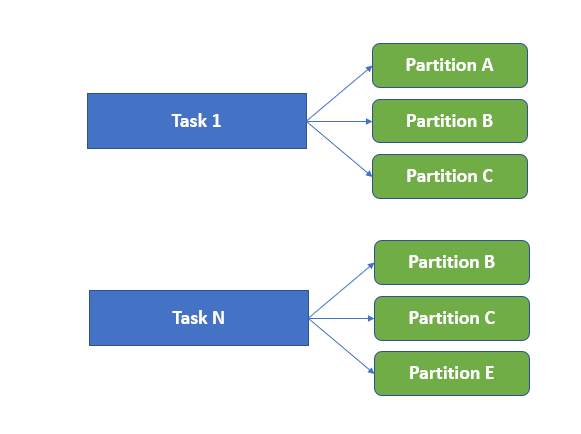
When a Spark writes data into a partitioned table, every task of the final stage has to distribute output rows based on the partition keys into individual files for every partition:
This process can be very slow when the data volume is large and if you look at the executors logs you can notice that they spend most of the time doing some sorting and spilling to disk:
INFO sort.UnsafeExternalSorter: Thread 61 spilling sort data of 132.0 MB to disk (0 time so far) INFO sort.UnsafeExternalSorter: Thread 61 spilling sort data of 132.0 MB to disk (1 time so far) INFO sort.UnsafeExternalSorter: Thread 61 spilling sort data of 132.0 MB to disk (2 times so far) INFO sort.UnsafeExternalSorter: Thread 61 spilling sort data of 132.0 MB to disk (3 times so far) ... INFO sort.UnsafeExternalSorter: Thread 61 spilling sort data of 6.1 GB to disk (16 times so far)
Additionally you can also observe the increasing spilling metrics for tasks:

The reason is that in Spark 2.4 a task writes one partition at a time using a single writer, so this approach requires the rows to be sorted by the partition key value.
See org.apache.spark.sql.execution.datasources.FileFormatDataWriter implementation for more details.
So now when you know that the writing into partitions involves the expensive sorting process, you may consider allocating more output tasks to speed up this process. As per my example above, having a single task to handle dozens of gigabytes may be too much.