Starting from EMR 5.32 and EMR 6.2 you can notice that Spark can launch much larger executors that you request in your job settings. For example, EMR created my cluster with the following default settings (it depends on the instance type and maximizeResourceAllocation classification option):
spark.executor.memory 18971M spark.executor.cores 4 spark.yarn.executor.memoryOverheadFactor 0.1875
But when I start a Spark session (pyspark command) I see the following:
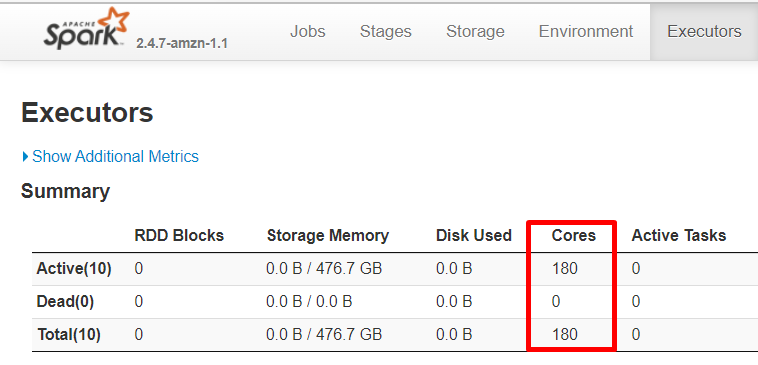
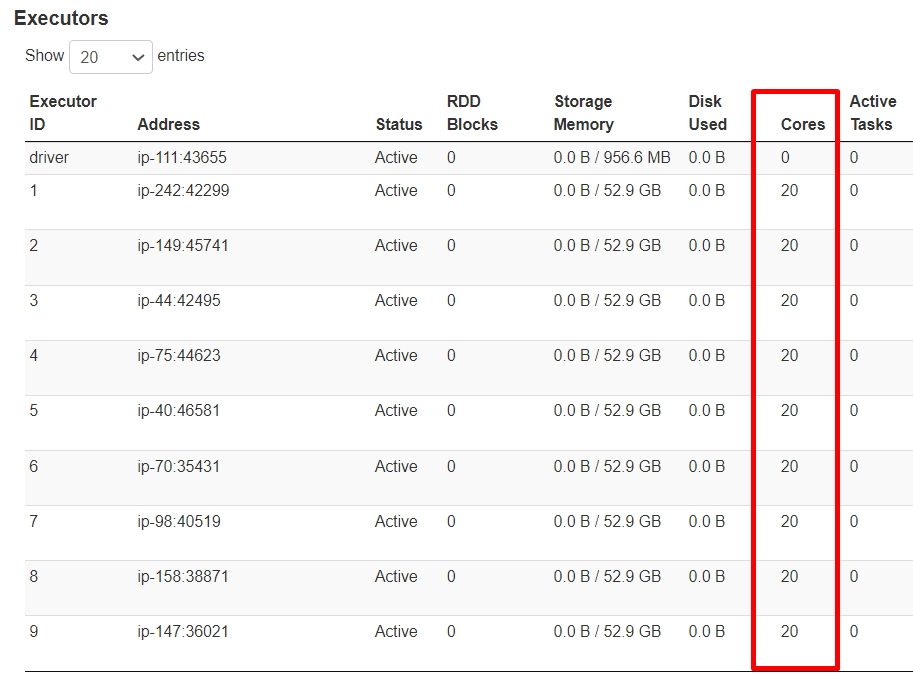
You can see that the executors with 20 cores (instead of 4 as defined by spark.executor.cores) were launched.
From the Spark driver log you can see:
INFO YarnAllocator: Will request up to 50 executor container(s), each with <memory:22528, max memory:2147483647, vCores:4, max vCores:2147483647> INFO YarnAllocator: Allocated container container_1645458567802_0606_01_000002 on host ip-242 for executor with ID 1 with resources <memory:112640, vCores:5> INFO YarnAllocator: Launching executor with 94854m of heap (plus 17786m overhead) and 20 cores
So 50 executors were initially requested with the required memory 22528 and 4 vcores as expected, but actually 9 executors were created with 112640 memory and 20 cores that is 5x larger. It should have created 10 executors but my cluster does not have resources to run more containers.
Note: The second log row specifies allocated vCores:5, it is because of using DefaultResourceCalculator in my YARN cluster that ignores CPU and uses memory resource only. Do not pay attention to this, the Spark executor will still use 20 cores as it reported in the third log record above.
The reason for allocating larger executors is that since EMR 5.32 and EMR 6.2 there is a Spark option spark.yarn.heterogeneousExecutors.enabled (exists in EMR only, does not exist in OSS Spark) that is set to true by default that combines multiple executor creation requests on the same node into a larger executor container.
So as the result you have fewer executor containers than you expected, each of them has more memory and cores that you specified.
If you disable this option (--conf "spark.yarn.heterogeneousExecutors.enabled=false"), EMR will create containers with the specified spark.executor.memory and spark.executor.cores settings and will not coalesce them into larger containers.