Amazon S3 is highly scalable distributed system that can handle extremely large volumes of data, can adapt to an increasing workload and provide quite good performance as a file storage.
But sometimes you have to tweak it to run faster that can be especially important for latency-sensitive applications.
Massive Writes and Slow Requests
Usually you use distributed application frameworks such Apache Spark, Flink or Hive that can massively write output data from many individual tasks (sometimes many thousand tasks) to S3.

But S3 offers 99.99% availability so on average you should expect some issues with every 10,000 requests to S3. They are not always HTTP 5xx errors, a few requests can just take much longer time to process (poor tail latency).
How longer? While most requests take 50-100 milliseconds, a few slow requests can take dozens of seconds or even minutes.
Of course the metrics can vary over time, but in my sample test I got the following results (I put data to almost random S3 prefixes from multiple instances to get the maximum performance):
request cnt cnt > 5 sec cnt > 10 sec cnt > 30 sec cnt > 60 sec
----------------- --- ----------- ------------ ------------ -------------
REST.PUT.PART 10,208,803 26,602 15,866 14 4
request time (millis): 25th percentile - 48
50th percentile - 80
95th percentile - 880
REST.PUT.PART is a request to upload a file part to S3, and you can see that in my test 0.16% of requests (15,866 of 10,208,803 or every 643 request) took more than 10 seconds, 0.00013% of requests (every 729,200 request) took more than 30 seconds.
And it is very important to note that the slow requests are not necessary large-size requests that naturally take longer time. In my case really small objects (less than 100 KB) got significant latency (often more than 30-60 seconds):
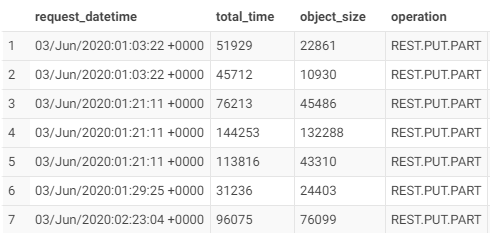
The more writes you have the more chances that a few of your requests will take longer time to process by S3.
For most distributed frameworks this brings up a problem as a few slow S3 write requests can delay the entire job or a stage as the overall execution time is defined by the slowest task. And this problem is very critical for latency-sensitive applications.
Request Timeouts
Fortunately, Amazon SDK provides a very nice feature – the request timeout. If a request does not complete within the specified timeout, an exception is raised and the request is retried (according to the reply policy and its settings).
A retried request is most likely to take a different route and often quickly succeed.
// aws-java-sdk-core/src/main/java/com/amazonaws/ClientConfiguration.java
/**
* The default timeout for a request. This is disabled by default.
*/
public static final int DEFAULT_REQUEST_TIMEOUT = 0;
/**
* The amount of time to wait (in milliseconds) for a request to complete before giving up and
* timing out. A value of 0 means infinity. Consider setting this if a harder guarantee is
* required on the maximum amount of time a request will take for non-streaming operations, and
* are willing to spin up a background thread to enforce it.
*/
private int requestTimeout = DEFAULT_REQUEST_TIMEOUT;
public ClientConfiguration withRequestTimeout(int requestTimeout) {
setRequestTimeout(requestTimeout);
return this;
}
The request timeout is disabled by default that’s why you can wait for a long time. If you write small chunks of data using S3 multipart upload, you can consider setting the timeout to 5 or 10 seconds.
This approach is an official Amazon S3 recommendation to get consistent latency for for latency-sensitive applications.
Hadoop Compatible File Systems
In most distributed frameworks you do not deal with Amazon SDK directly, and you cannot easily fine-tune the client settings. Hadoop libraries are widely used, so all operations are handled by S3AFileSystem or equivalent class.
Only starting from Hadoop 3.3 you can set fs.s3a.connection.request.timeout option directly (HADOOP-16792).
In earlier versions of Hadoop there are many S3 related settings, but there is no request timeout option. Fortunately there is a relatively easy workaround. The default client is defined by DefaultS3ClientFactory that can be redefined by the fs.s3a.s3.client.factory.impl option.
Implement a class similar to DefaultS3ClientFactory from org.apache.hadoop.fs.s3a package and add:
public static final String REQUEST_TIMEOUT = "fs.s3a.connection.request.timeout";
private static void initConnectionSettings(Configuration conf, ClientConfiguration awsConf) {
...
awsConf.setRequestTimeout(intOption(conf, REQUEST_TIMEOUT, DEFAULT_REQUEST_TIMEOUT, 0));
...
}
Build and use this S3 custom factory in your application.
Request Timeout in Action
Now when you set a request timeout you can observe the following from S3 access logs (I configured the client with 10 seconds request timeout):

You can see requests to load a 8 MB file. The first PUT.PART operation started at 03:27:47 and straggled for about 30 seconds, but the second PUT.PART was initiated right after 10 seconds at 03:27:57 and completed fast. So the final commit request (REST.POST.UPLOAD) could end faster.