Usually Hadoop is able to automatically recover cluster nodes from Unhealthy state by cleaning log and temporary directories. But sometimes nodes stay unhealthy for a long time and manual intervention is necessary to bring them back.
In one Hadoop cluster I found a node that has been running in unhealthy state for many days:
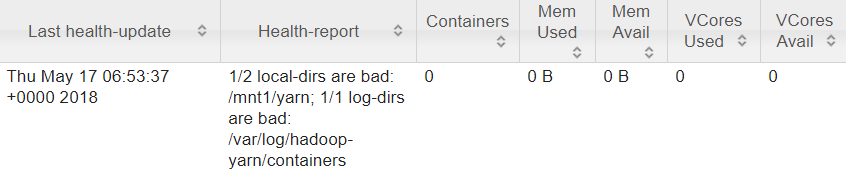
The Unhealthy state means that node is reachable, it runs the YARN NodeManager but it can not be used to schedule task execution (run YARN containers) for various reasons. In my case the log message shows that there is no enough disk space on the node.
Connecting to the node I see that /mnt1 and /var have enough space while /emr is full:
$ ssh -i "private_key_file" root@ip_address $ df -h Filesystem Size Used Avail Use% Mounted on ... /dev/xvda1 50G 6.6G 43G 14% / /dev/xvdb1 5.0G 5.0G 20K 100% /emr /dev/xvdc 153G 9.3G 144G 7% /mnt1
/emr directory is used by the EMR services managing the node:
$ du -sh /emr/* 16K /emr/apppusher 143M /emr/instance-controller 565M /emr/instance-state 4.1G /emr/logpusher 177M /emr/service-nanny 56K /emr/setup-devices du -sh /emr/logpusher/* 8.0K /emr/logpusher/db 0 /emr/logpusher/lib 4.1G /emr/logpusher/log 4.0K /emr/logpusher/run
For some reason logpusher was unable to rotate and clean its logs, so I removed them manually.
Then I noticed that the EMR services were not running on this node:
$ sudo /etc/init.d/instance-controller status Not Running [WARNING] $ sudo /etc/init.d/service-nanny status Not Running [WARNING] $ sudo /etc/init.d/logpusher status Not Running [WARNING]
So I had to start them manually (replacing status with start in the commands above). The last step was to restart the NodeManager:
$ sudo stop hadoop-yarn-nodemanager $ sudo yarn nodemanager &
And now the node is back.