Traditional data warehouses require you to explicitly specify partition columns for tables using the PARTITION BY clause. There is no PARTITION BY clause in the CREATE TABLE statement in Snowflake although it still heavily relies on partitions.
I already wrote about partitions in Snowflake (see, MIN/MAX Functions and Partition Pruning in Snowflake) but in this article I am going to investigate some more details.
Partitioning
Data warehouses store large volumes of data, sometimes they keep historical data for many years. At the same time data analysts rarely need to query all data, in most cases they are interested in data for recent days, weeks or just short periods in the past.
Table partitioning i.e dividing the large table into multiple smaller parts on columns such as event_date or order_date comes very handy. For example, when you run a query:
SELECT city, product, COUNT(*) FROM events WHERE event_date BETWEEN '2019-11-25' AND '2019-11-29' and event_type = 'LOGIN' GROUP BY city, product
The database needs to read data for 5 days only, not the entire table.
Such optimization is called partition pruning, and since the daily volume is still high and can contain millions of rows the partitioning is much more efficient than indexes that are used in transactional (OLTP) databases.
Micro-Partitions
Although you do not explicitly specify partitions in Snowflake, all data are automatically loaded into partitions, called micro-partitions in Snowflake.
Each micro-partition contains between 50 and 500 MB of uncompressed data (but stored with compression) organized in a columnar fashion, and for each micro-partition Snowflake stores the range of values for each column that helps perform partition pruning for queries.
Unlike tables in traditional data warehouses that typically have a relatively small number of partitions (for example, 1 partition per day and per product), a table in Snowflake can easily have millions of partitions.
Clustering
When new data continuously arrived and loaded into micro-partitions some columns (for example, event_date) have constant values in all partitions (naturally clustered), while other columns (for example, city) may have the same values appearing over and over in all partitions:

Now if you run a query:
SELECT product, COUNT(*) FROM events WHERE event_date = '2019-11-28' GROUP BY product
Snowflake will read data only from partitions P1, P2 and P3. But consider another query:
SELECT product, COUNT(*) FROM events WHERE city = 'Amsterdam' GROUP BY product
Although we applied a filter on the city column, Snowflake still has to read data from all partitions except P5, since data is scattered across almost all partitions.
What about the following query:
SELECT product, COUNT(*) FROM events WHERE city = 'Dublin' GROUP BY product
Snowflake still needs to read data from P5 and P6 partitions. Snowflake stores MIN/MAX column statistics for a partition, so it has to read P6 since the value Dublin is within its MIN (Amsterdam) and MAX (Florence).
Note: a bloom filter can prevent from reading P6 in most cases (but not in 100% as it is a probabilistic data structure with possible false positives), but at the time of writing Snowflake does not clearly state whether bloom filters are used for partition pruning, and my tests showed that partitions were scanned (according to the Query Profile). Of course, this can be improved in future.
So you can say that table is not well-clustered with regards to the city column, and may benefit from clustering.
Snowflake allows you to define clustering keys, one or more columns that are used to co-locate the data in the table in the same micro-partitions. For example, a simplified view:

Now a query with a filter on the city column will fetch much less data.
Constant Partitions
“Well-clustered” is not a table property, clustering is defined with regards to the specific columns, and a table can be well-clustered for one column and bad-clustered for another column.
The same applies to the term constant partition in Snowflake. A partition is constant with regards to the column if all rows of the partition have the same single value for this column:
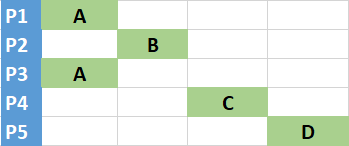
Why is it important? If all partitions are constant in the table, then a query with a filter on this column will only require to read partitions with 100% rows that satisfy the condition, it can skip reading all other partitions, i.e. filtering is a pure metadata operation.
If the picture above, all partitions are constant and a query with the filter type = 'A' will require to read partitions P1 and P3 only that have value ‘A’ in all their rows. It is the perfect scenario (remember, with regards to the column type only).
Partition Overlaps
Even if partitions do not have constant values they still maybe not overlapping:

If the picture above, a query with the filter type = 'A' requires to read partitions P1 and P4 only although it has to read and then filter out the rows with value 'B' that are also stored in these partitions.
Consider another example, now all partitions overlap:
Although all 5 partitions now overlap a query with the filter type = 'B' has only to read 2 partitions P1 and P2. Now it has to read and filter out the rows with values 'A' and 'C'.
Clustering Depth
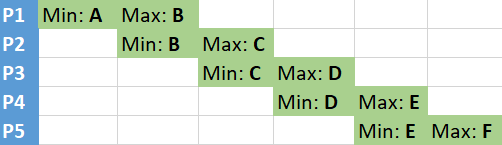
Consider one more example:

All 5 partitions still overlap, but now a query with the filter type = 'B' has to read the entire data from all partitions! So although the partitions have the same overlap count in last 2 examples, they differ in the clustering depth.
If you take all overlapping micro-partitions in a table and stack them together according to the MIN and MAX values of the specific column, you can calculate the clustering depth with regards to this column.
A simplified calculation:

To some extent, the clustering depth can tell you how many partitions a query with a filter on this column will read on average if the filter falls into overlapping micro-partitions.
Snowflake provides a function to calculate the clustering information on tables and specific columns:
SELECT system$clustering_information('events', '(event_date)')
Sample result for the event_date column:
{
"cluster_by_keys" : "LINEAR(EVENT_DATE)",
"total_partition_count" : 2672931,
"total_constant_partition_count" : 2598036,
"average_overlaps" : 40538.536,
"average_depth" : 31064.0861,
"partition_depth_histogram" : {
"00000" : 0,
"00001" : 2598003,
"00002" : 0,
"00003" : 0,
"00004" : 3,
"00005" : 0,
...
"00015" : 0,
"00016" : 0,
"00512" : 1,
"02048" : 4423,
"04096" : 11403,
"08192" : 3896,
"32768" : 7955,
"65536" : 47247
}
}
Here you can see that most partitions are constant (2.5 millions or 97%) for the event_date column (clustering depth is equal to 1). There are 47,247 partitions that have the clustering depth between 32,768 and 65,535.
Let’s check the city column:
SELECT system$clustering_information('events', '(city)')
The result is as follows:
{
"cluster_by_keys" : "LINEAR(CITY)",
"total_partition_count" : 2673936,
"total_constant_partition_count" : 0,
"average_overlaps" : 2673935.0,
"average_depth" : 2673936.0,
"partition_depth_histogram" : {
"00000" : 0,
"00001" : 0,
"00002" : 0,
"00003" : 0,
"00004" : 0,
"00005" : 0,
...
"00016" : 0,
"4194304" : 2673936
}
}
There are no constant partitions now, and the clustering depth is equal to the number of partitions in the table which means that a query with a filter on city column will always read the entire table of 2.6 million of partitions (unless there are other filters in the query).
Conclusion
- Clustering may improve performance of your queries, but since it is defined with regards to the specific columns, you should analyze your queries. A table can be well-clustered for some queries and bad-clustered for others.
- The partition overlap is less important than the clustering depth, but remember that the clustering depth is calculated for non-constant partitions only, so you should know their fraction among all partitions in the table.