Memory allocation in Hadoop YARN clusters has some drawbacks that may lead to significant cluster under-utilization and at the same time (!) to large queues of pending applications.
So you have to pay for extra compute resources that you do not use and still have unsatisfied users. Let’s see how this can happen and how you can mitigate this.
Fixing “Not Enough Memory” Problems for Queries
Consider SQL queries executed using Apache Hive, a Hadoop YARN application that allocates containers for distributed job execution on multiple nodes.
Heavy SQL queries often cause java.lang.OutOfMemoryError: Java heap space errors in containers that most people first try to solve by allocating larger containers:
set hive.tez.container.size = 4096; select ...
Sometimes it may take a few iterations to find the proper container size, but usually it helps and the query succeeds.
But what if you set the container size 4096 MB or 8192 MB but the query could complete successfully even with 2048 MB?
Cluster Utilization
Assume you have a 100-node cluster with 16 GB of memory and 8 vCPU on every node. For example, initially your query requests 400 containers with the default size of 1 GB:

You can see that the cluster has plenty of resources to run other applications – 1,200 GB memory and 400 vCPU. But your query fails with Java heap space error and you decide to use 4 GB containers:

Now it takes all cluster memory leaving no space for other queries.
Of course, depending on the cluster scheduler you use (Capacity Scheduler, Fair Scheduler i.e.) and the job queue configuration (priority, container preemption i.e) other applications still can get their resources but anyway in that case your query will not be able to run 400 containers concurrently anymore.
Unlike large multi-tenant on-premise Hadoop clusters, a cluster in cloud is typically allocated for a single team, so all members have the same priority and submit queries to the same queue.
In this case if your cluster uses Capacity Scheduler and you submit your query first and take all cluster resources then other team members will have to wait until your query completes (their queries will be in Application Pending state in YARN).
Memory Reservation in YARN
YARN knows how much memory is available in the cluster, and if an application requests containers of the specified size, YARN just decreases the available memory by this amount. If there is no memory left other applications have to wait (or preempt running containers).
The problem is that the requested memory does not necessarily equal to the used memory.
YARN treats memory as a logical resource with no connection to its real physical consumption. Since YARN applications tend to over-request memory resources (using 4 GB containers when 2 GB is enough) in order to not fail with out-of-memory errors this may lead to significant cluster under-utilization as not used memory is not available to other applications.
Real World Scenario
One of my Hadoop clusters is created in Amazon EMR using the following instances:
| EC2 Type | CPU, Memory in EC2 | CPU, Memory in YARN |
| m4.xlarge | 8 vCore, 16 GB | 8 Virtual Cores, 12 GB |
| m4.2xlarge | 16 vCore, 32 GB | 16 Virtual Cores, 24 GB |
You can see that not all memory is available for YARN containers, and 25% of memory is reserved for OS and other processes.
This cluster runs only Apache Hive queries using Apache Tez engine that allocates 1 vCPU (Virtual Core) per container, so 1.5 GB is the ideal container size for this cluster.
I noticed that when the cluster is saturated (no more free memory in YARN) it runs a maximum of 563 containers (and vCPU) while 1,512 vCPU are still available but never used.
Additionally looking at the historical cluster statistics in Ganglia I see that a lot of memory is free even when the cluster is “saturated” in YARN:
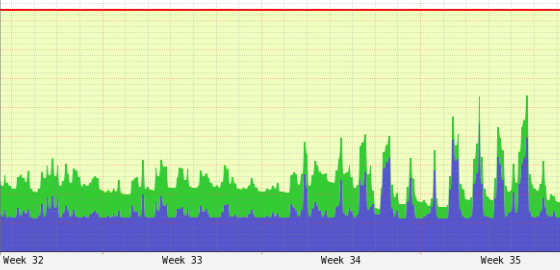
CPU is not busy event in YARN, and Ganglia just confirms this:
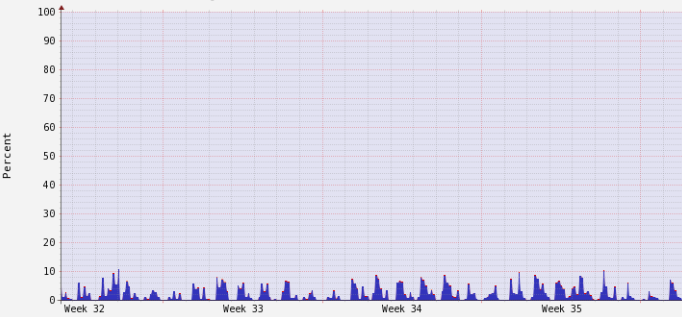
So we have the “saturated” cluster from YARN point of view while it still has plenty of free resources.
Increasing Cluster Capacity without Changing Hardware or Adding More Nodes
It would be ideal if containers are sized based on the actual memory requirements, but for many reasons it is hard to achieve in reality.
Another solution is to tell YARN that it has more memory. But remember, you should do this very carefully constantly monitoring the cluster load metrics at the OS level.
Steps are as follows:
1. Modify yarn-site.xml configuration file on every node.
yarn.nodemanager.resource.memory-mb option specifies how much memory is available for the YARN containers on this node:
<property> <name>yarn.nodemanager.resource.memory-mb</name> <value>12288</value> </property>
The following update_yarn_site_xml.sh shell script increases the value:
config_file='/etc/hadoop/conf/yarn-site.xml'
config_file_new='/etc/hadoop/conf/yarn-site_new.xml'
update_script="
import sys
config_file = '$config_file'
variable = '<name>yarn.nodemanager.resource.memory-mb</name>'
old_value = '<value>12288</value>'
new_value = '<value>16384</value>'
with open(config_file) as file:
line = file.readline()
while line:
line = file.readline()
# Find variable and replace its value
if line.find(variable) != -1:
sys.stdout.write(line)
# Read old value, make sure it contains the expected old value and replace it
line = file.readline()
if line.find(old_value) != -1:
print(' ' + new_value)
else:
sys.stdout.write(line)
# Forward line as is
else:
sys.stdout.write(line)
"
python -c "$update_script" > $config_file_new
mv -f $config_file_new $config_file
Then you have to restart NodeManager:
$ stop hadoop-yarn-nodemanager $ start hadoop-yarn-nodemanager
In you have many nodes you can running these steps over SSH for every node:
$ ssh -i privateKey hadoop@node_ipaddr 'sudo bash -s' < update_yarn_site_xml.sh
In my case this helped me increase the cluster capacity by more than 30% so it can allocate more containers concurrently at peak load, and still not to be saturated from the OS perspective – have at least 20% of available CPU and memory.
In some extreme cases YARN can even have more memory than physically available in the cluster. To some extent it reminds OS virtual/physical address spaces concept.
Please remember that this technique should be applied very carefully for specific clusters exactly knowing and constantly monitoring their historical and current CPU/memory workload using OS tools, not only YARN. Especially you should have pay attention when your cluster is at its maximum load.