One of our event tables is very large, it contains billions of rows per day. Since the analytics team is often interested in specific events only it makes sense to process the raw events and generate a partition for every event type. Then when a data analyst runs an ad-hoc query, it reads data for the required event type only increasing the query performance.
The problem is that there are 3,000 map tasks are launched to read the daily data and there are 250 distinct event types, so the mappers will produce 3,000 * 250 = 750,000 files per day. That’s too much.
Reducing the number of map tasks is not always an option as it increases the execution time, and the number of files is still high (500 tasks will produce 125,000 files per day), while our goal is to have about 500-700 files daily for this single table.
A well-known solution for this problem is to force a reduce phase. But what if the data is highly skewed, for example, when there are few event types having hundreds of millions rows, while others just have a few million rows?
| event_name | count |
|---|---|
| LEVEL_CHANGE | 397,121,363 |
| LOGIN | 126,904,308 |
| … | |
| STATUS_CHANGE | 1,376,847 |
Let’s see how Apache Pig deals with this problem. Here is a Pig code excerpt:
raw = LOAD 'events_raw' USING org.apache.hive.hcatalog.pig.HCatLoader();
-- event_name and event_dt are partition columns in Hive
events = FOREACH raw GENERATE record_id, ... , event_name, event_dt;
events = ORDER events BY event_name PARALLEL 500;
STORE events INTO 'events' USING org.apache.hive.hcatalog.pig.HCatStorer();
Here is the Tez DAG for this job:

Vertex Scope-80
Scope-80 reads the source data from S3 and writes them to local disks on the compute nodes:
| RACK_LOCAL_TASKS | 3,047 |
| FILE_BYTES_WRITTEN | 1,233,777,735,221 |
| S3N_BYTES_READ | 356,624,141,572 |
| INPUT_RECORDS_PROCESSED | 3,028,747,949 |
| Duration | 585 secs |
Scope-80 writes output for 2 vertices – Scope-89 and Scope-99:
[scope-99:OUTPUT:0:org.apache.tez.runtime.library.output.UnorderedKVOutput], [scope-89:OUTPUT:209715200:org.apache.tez.runtime.library.output.OrderedPartitionedKVOutput]
From DAG you can obtain more details:
{"inputVertexName": "scope-80",
"outputVertexName": "scope-99",
"dataMovementType": "ONE_TO_ONE",
"dataSourceType": "PERSISTED",
"schedulingType": "SEQUENTIAL",
"edgeSourceClass": "org.apache.tez.runtime.library.output.UnorderedKVOutput",
"edgeDestinationClass": "org.apache.tez.runtime.library.input.UnorderedKVInput"},
{"inputVertexName": "scope-80",
"outputVertexName": "scope-89",
"dataMovementType": "SCATTER_GATHER",
"dataSourceType": "PERSISTED",
"schedulingType": "SEQUENTIAL",
"edgeSourceClass": "org.apache.tez.runtime.library.output.OrderedPartitionedKVOutput",
"edgeDestinationClass": "org.apache.tez.runtime.library.input.OrderedGroupedKVInput"}
So what are the Scope-89 and Scope-99?
Vertex Scope-89
Scope-89 is the Sampler, its goal is to provide an estimation about the key distribution i.e. estimation how many rows each event_name has.
| TASKS | 1 |
| FILE_BYTES_READ | 931,505 |
| FILE_BYTES_WRITTEN | 913,571 |
| REDUCE_INPUT_GROUPS | 142 |
| REDUCE_INPUT_RECORDS | 304,700 |
| NUM_SHUFFLED_INPUTS | 3,047 |
| OUTPUT_RECORDS | 1 |
| OUTPUT_BYTES | 138,479 |
| Duration | 146 secs |
Note that the sampler reads just 100 rows from each map task of Scope-80, so it reads only 3047 * 100 = 304,700 rows to build the quantile file containing the key distribution estimation.
Vertex Scope-99
Scope-99 is similar to Scope-80, it reads the filtered source data but now it reads them from local disks as Map Output from Scope-80 not from S3. This is ONE_TO_ONE read between Scope-80 and Scope-99.
But in addition to that, Scope-99 gets the key distribution generated by Scope-89, and it uses it to partition data for the Reducer at Scope-11 performing the ORDER statement.
Usually when any Map Reduce framework partitions data by a key, it puts all rows having the same key into the same partition bucket. This does not work well for skewed data i.e. when few keys have much more records than all others combined.
But for ORDER statement it is not necessary to put all rows for the same key into one Reducer, and this is what the Weighted Range Partitioner utilizes to balance the reducers.
Assume, there are keys A, B, C and D having 5, 50, 5 and 10 rows respectively. Instead of sorting data in 4 reducers (and having significant skew in Reducer 2 sorting 50 rows of key B), we can sort data in 7 balanced reducers processing 10 rows each:
- Key A – Rows go to Reducer 1 with 100% probability
- Key B – Rows go to Reducers 1, 2, 3, 4, 5 and 6 with probabilities 10%, 20%, 20%, 20%, 20% and 10%, respectively
- Key C – Rows go to Reducer 6 with 100% probability
- Key D – Rows go to Reducer 7 with 100% probability
Note that reducers process the same number of rows, multiple reducers can process the same key, but at the same time the keys do not overlap in reducers to preserve the global sort order.
Vertex Scope-101
Scope-101 is the Reduce stage that performs the sorting. It gets evenly distributed data from the previous stage:
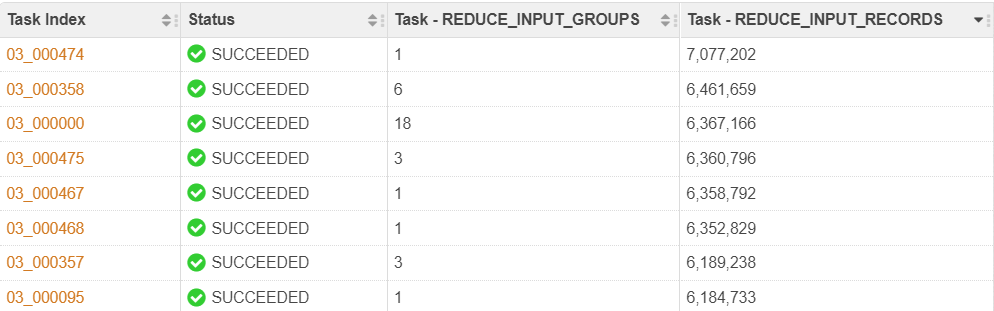
You can see the largest number of rows that goes to a reducer is just 7,707,202, and it is not 397,121,363 that we have for the largest key LEVEL_CHANGE. Also you can see that all other reducers receive similar number of rows.
REDUCE_INPUT_GROUP shows that many reducers process multiple keys.
Looking at created output files you can see that the number of files 763 is greater than the number of reducers 500:
$ aws s3 ls s3://cloudsqale/hive/events.db/events/ --recursive | grep event_dt=2019-01-24 | wc -l 763
You can confirm this by looking at the files created in every partition:
... 1427438707 event_name=LEVEL_CHANGE/event_dt=2019-01-24/part-v003-o000-r-00100 3058972652 event_name=LEVEL_CHANGE/event_dt=2019-01-24/part-v003-o000-r-00101 3060453360 event_name=LEVEL_CHANGE/event_dt=2019-01-24/part-v003-o000-r-00102 3061732096 event_name=LEVEL_CHANGE/event_dt=2019-01-24/part-v003-o000-r-00103 3061541716 event_name=LEVEL_CHANGE/event_dt=2019-01-24/part-v003-o000-r-00104 3061114642 event_name=LEVEL_CHANGE/event_dt=2019-01-24/part-v003-o000-r-00105 3062288248 event_name=LEVEL_CHANGE/event_dt=2019-01-24/part-v003-o000-r-00106 3062339121 event_name=LEVEL_CHANGE/event_dt=2019-01-24/part-v003-o000-r-00107 3063282675 event_name=LEVEL_CHANGE/event_dt=2019-01-24/part-v003-o000-r-00108 1963942631 event_name=LEVEL_CHANGE/event_dt=2019-01-24/part-v003-o000-r-00109 ...
This shows that the LEVEL_CHANGE event data were written by 10 reducers (r-00100 to r-00109).
So the Weighted Range Partitioner in Pig can help you reduce the number of output file by using the ORDER statement, and at the same it works well when data are highly skewed.